TL;DR (according to DeepSeek):
We explores methods to augment small datasets of instruction-trajectory pairs for training instruction-following policies by leveraging large, unannotated play trajectories. We propose Play Segmentation (PS), a probabilistic model that segments long trajectories into meaningful, instruction-aligned segments using only short, annotated segments for training. PS outperforms adapted video segmentation methods like UnLoc and TriDet, improving policy performance in both a game environment (BabyAI) and a robotic simulation (CALVIN). The results show that PS can recover policy performance equivalent to using twice the amount of labelled data, highlighting the importance of accurate segmentation for data augmentation. The approach addresses the challenge of limited annotated data in training instructable agents, offering a scalable solution for semi-supervised learning in robotics and gaming.
Setup - Play Data
Long play trajectories of agents acting in the environment.
Some subsegments are labelled by humans with the corresponding instruction.
Example of a play trajectory with the corresponding annotated segments can be seen on the left (Annotations appear below the image once they are active.).
Methodology
1. Train Segmentation Models
We introduce Play Segmentation (PS), a probabilistic model trained on individual instruction segments, which uses dynamic programming to find optimal segmentations of longer trajectories. PS is designed to generalise from short, annotated segments to longer, unsegmented play trajectories. Further we adapt video segmentation methods (UnLoc and TriDet) to crop and label segments from play trajectories.
2. Segment Play Trajectories
We segment play trajectories of the CALVIN and BabyAI environment. Below some example results:
Play trajectories are segmented into meaningful segments that align with their instruction label. Filtering by the confidence of the labelling model is important to avoid wrongly labelled segments. In environments where the instruction segments have similar length cropping large random segments into instruction segments via video segmentation methods (UnLoc and TriDet) can be a good alternative. However, in environments where the instruction segments have varying lengths, Play Segmentation (PS) leads to better aligned instruction segments.
3. Train Policies via Imitation Learning on Augmented Dataset
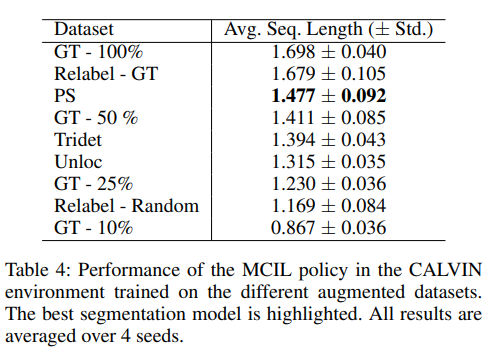
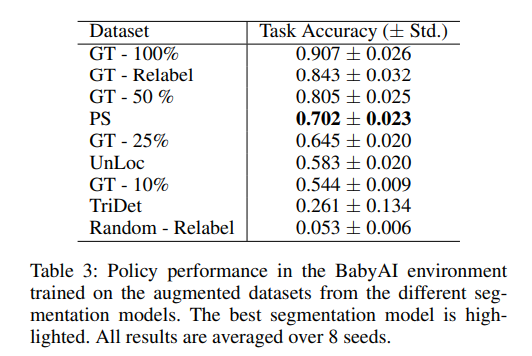
We train the segmentation models based on 25% (10%) of the available annotated data in CALVIN (BabyAI) and augment this subset with labelled segments extracted from the play trajectories such that the initial dataset size is reached again. The results show that augmenting the dataset with labelled segments extracted using Play Segmentation (PS) significantly improves policy performance compared to other methods. In both the BabyAI and CALVIN environments, PS outperforms policies trained on datasets augmented with segments from video segmentation methods like UnLoc and TriDet. PS also achieves performance close to or better than policies trained on significantly larger amounts of the original labelled data. These findings highlight PS's effectiveness in accurately segmenting play trajectories and its ability to enhance policy performance through data augmentation, even when starting with limited annotated data.