TL;DR (according to DeepSeek):
In this paper, we developed a generalist agent capable of handling multiple sequential decision-making tasks that involve different action spaces but share observation spaces, like images. We extend the universal policy framework by incorporating a diffusion-based planner that generates observation sequences conditioned on both task descriptions and agent-specific information. By pooling data from various agents, our method shows positive transfer, enhancing task performance compared to training on individual agent datasets. We investigate different ways to condition the planner using agent-specific information (e.g., agent ID, action space representation, example trajectories) and compare the universal policy framework with imitation learning baselines.
Examples
Example trajectories generated for 6 different agents in the BabyAI environment generated by a single Universal Cross Agent Policy (UCAP) trained on a joint dataset of all agents. The following action spaces are displayed:

"Standard" Action Space
Go to the yellow box
"No left turns" Action Space
Go to a blue key
"No right turns" Action Space
Go to the grey key
"Diagonal" Action Space
Go to the grey box
"WSAD" Action Space
Go to the yellow ball
"Dir8" Action Space
Go to a blue box
Methodology
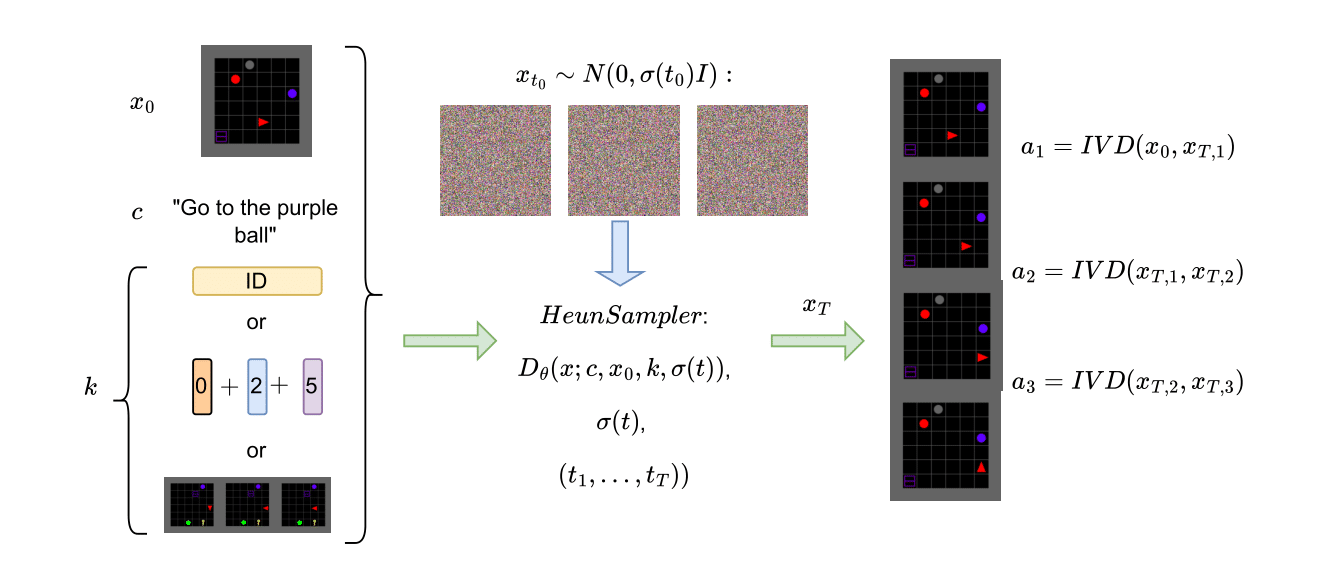
We train a diffusion planner on a mixed dataset consisting of trajectories of different agents. The planner generates observation sequences conditioned on the starting observation, task, and agent information (e.g., agent ID, action space, or example trajectories). Subsequently an agent specific inverse dynamics models labels these sequences with actions for the corresponding agent type.
Comparison to Imitation Learning Approaches
We compare the universal policy approach to imitation learning (IL) baselines in multi-agent settings with heterogeneous datasets. The IL baselines include: (1) standard IL trained on single or mixed datasets, (2) IL with a union of action spaces and agent ID encoding, and (3) IL with separate agent heads but a shared convolutional backbone. All baselines are also evaluated with fine-tuning on smaller agent-specific datasets. Results show that both IL variants exhibit positive transfer, improving task completion rates when trained on mixed datasets compared to single-agent datasets. However, without fine-tuning, IL baselines fail to generalize to unseen agents. The universal policy, conditioned on action space information, outperforms IL baselines, in the more complex environment, and shows better fine-tuning performance. None of the methods generalize to unseen agents without fine-tuning, but the universal policy adapts more effectively, suggesting it is easier to fine-tune than learning new agent heads or adapting to new action spaces.